The open source model surpassed GPT-3.5, and the measured results of MoE were released. Netizen: OpenAI has no moat more and more.
Keresey fish and sheep originated from Aofei Temple.
Quantum bit | WeChat official account QbitAI
A mysterious magnetic link detonated the entire AI circle. Now, the official evaluation results have finally come:
The first open source MoE model, Mixtral 8x7B, has reached or even surpassed the level of Llama 2 70B and GPT-3.5.
(Yes, it is the same scheme of the rumored GPT-4. )
And because it is a sparse model, it only takes 12.9B parameters to process each token, and its reasoning speed and cost are equivalent to those of the dense model of 12.9 b.
As soon as the news came out, it once again set off a discussion boom on social media.

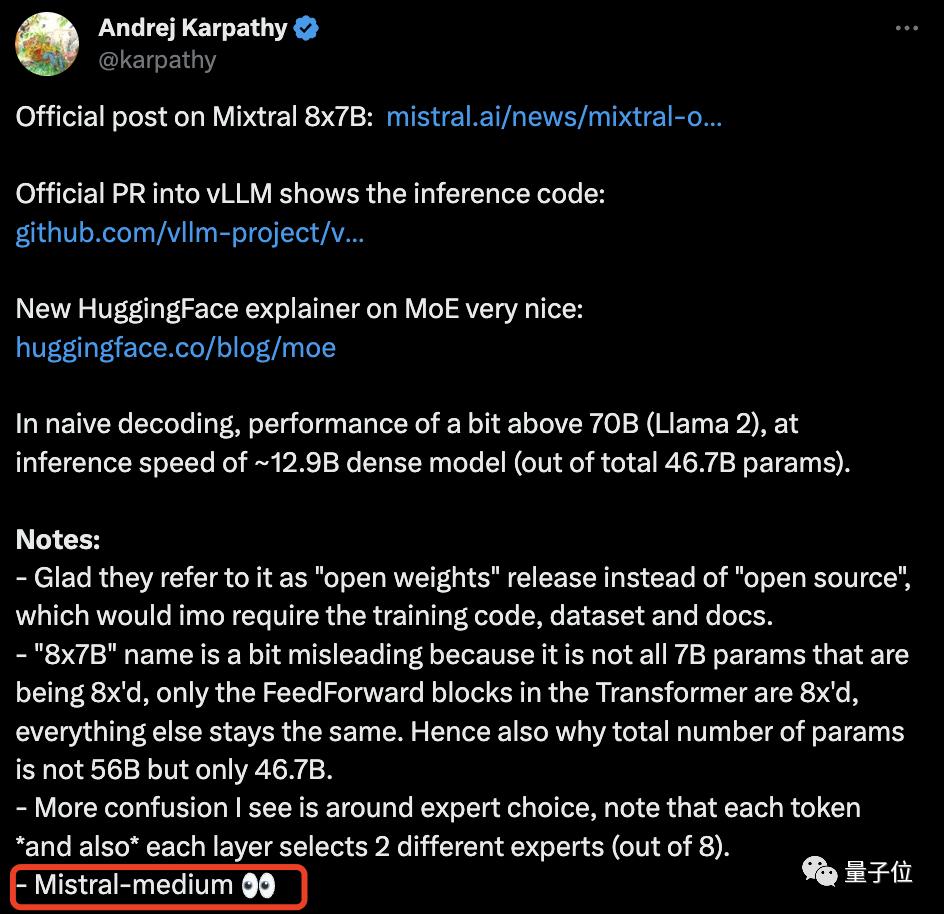
Andrej Karpathy, the founding member of OpenAI, rushed to the scene to sort out his notes at the first time, and also highlighted the key points: the strongest model revealed by this "European version of OpenAI" is only a "medium cup".
P.s. Mixtral 8×7B is even just a small cup …
Jim Fan, an AI scientist in NVIDIA, praised:
Every month, there are more than a dozen new models, but few of them can really stand the test, and even less can attract the enthusiastic attention of the big guys.

And this wave, not only the company Mistral AI behind the model has attracted great attention, but also the MoE(Mixture of Experts) has once again become the hottest topic in the open source AI community.
HuggingFace officially released an analysis blog post of MoE while it was hot, which also had the effect of "forwarding like a tide".

It is noteworthy that Mistral AI’s latest valuation has exceeded $2 billion, an increase of more than seven times in just six months …
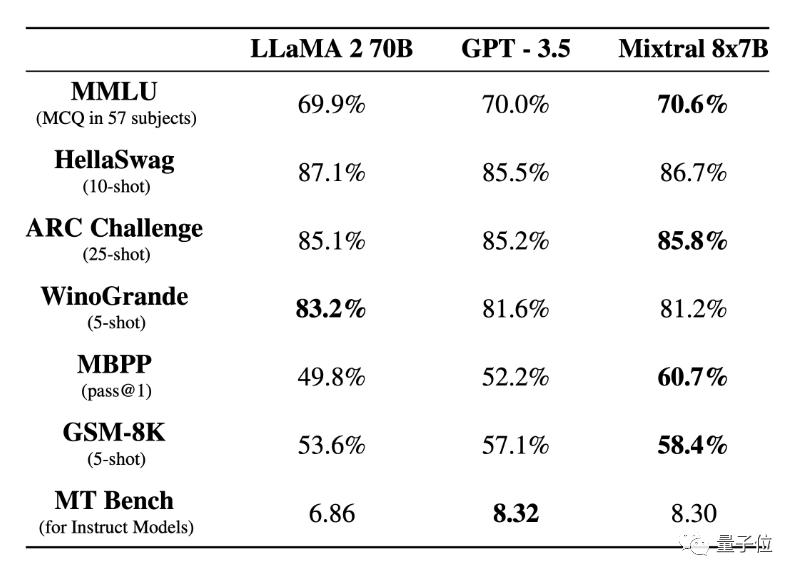
Basically surpass Llama 2 70B.
Speaking of it, Mistral AI is a company that doesn’t take the usual path. The front foot of the big factory next door just held a press conference with great vigour, and slowly made a model, but they can pour out the program directly:
First, I left the link for open download, and then I mentioned PR to vLLM project (a large model reasoning acceleration tool). Finally, I remembered to publish a technical blog to give my own model a serious official announcement.
△ The model was originally released by Aunt Jiang.
Then let’s take a look at what information is given by the official, and what is the difference from the details that the people who eat melons themselves have pulled out in the past two days.
First of all, the official confidently said:
Mixtral 8×7B is superior to Llama 2 70B in most benchmark tests, and the reasoning speed is six times faster.
It is the most powerful open weight model with loose license and the best cost-effective choice.
Specifically, Mixtral adopts sparse mixed expert network, which is a decoder-only model. Among them, the feedforward block will choose from eight different parameter groups-
That is to say, in fact, Mixtral 8×7B is not a collection of eight 7B parameter models, but there are only eight different feedforward blocks in the Transformer.
This is why the parameter quantity of Mixtral is not 56B, but 46.7B.

Its characteristics include the following aspects:
It performs better than LLMA 270B in most benchmark tests, even enough to beat GPT-3.5.
The context window is 32k.
Can handle English, French, Italian, German and Spanish.
Excellent in code generation.
Follow the Apache 2.0 license (free commercial use)
The specific test results are as follows:
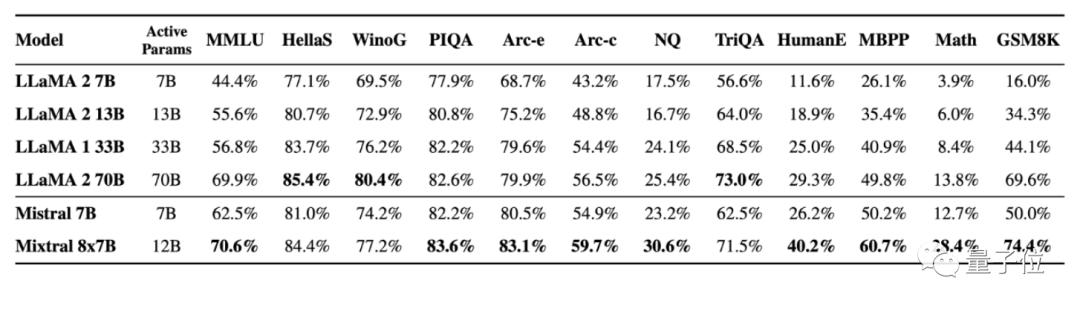
In addition, in the aspect of hallucination, the performance of Mixtral is also due to Llama 2 70B:
The score on the TruthfulQA benchmark is 73.9% vs 50.2%; Show less prejudice on BBQ benchmark; On BOLD, Mixtral shows more positive emotions than Llama 2.
This time, together with the basic version of Mixtral 8×7B, there is also the version of Mixtral 8x7B Instruct. The latter has been optimized by SFT and DPO, and scored 8.3 on MT-Bench, which is similar to GPT-3.5 and superior to other open source models.

At present, Mistral has officially announced the launch of API service, but it is still an invitation system, and uninvited users need to wait in line.
It is worth noting that the API is divided into three versions:
Mistral-tiny, the corresponding model is Mistral 7B Instruct;;
Mistral-small, the corresponding model is Mixtral 8×7B; released this time;
Mistral-medium, the corresponding model has not been published, but the official revealed that its score on MT-Bench is 8.6.
Some netizens directly pulled GPT-4 and compared it. It can be seen that the middle cup model scored more than GPT-4 on WinoGrande (common sense reasoning benchmark).

In terms of price, the input and output prices of small cups to medium cups are 0.14 ~ 2.5 euros and 0.42~7.5 euros per million tokens respectively, and the embedded model is 0.1 euros per million tokens (1 euro is about 7.7 RMB).

The online version can only be experienced on third-party platforms (Poe, HuggingFace, etc.).
Can read Chinese, but is reluctant to speak it.
Although the official announcement didn’t say that it supports Chinese, our actual measurement (the online version in HuggingFace Chat, the model is the Instruct version) found that Mixtral already has a certain Chinese ability at least at the understanding level.
On the generation level, Mixtral is not inclined to answer in Chinese, but it can also get a Chinese reply if it is specified, but there are still some mixed Chinese and English situations.

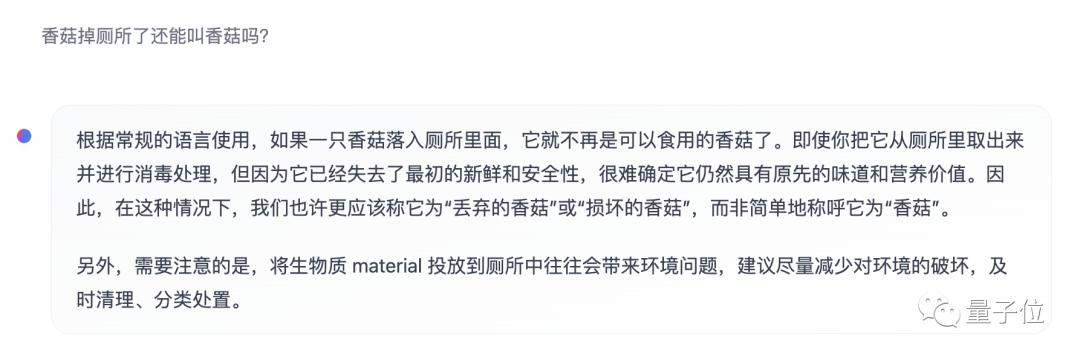
In the face of more "retarded" questions, although Mixtral’s answer is quite satisfactory, it seems that at least the literal meaning has been understood.
Mathematically, in the face of the classic problem of chickens and rabbits in the same cage, Mixtral’s answer is completely correct from the process to the result.

Even for advanced mathematics problems, such as complex function derivation, Mixtral can give correct answers, and what is more commendable is that there is no problem in the process.

This official announcement specifically emphasized that Mixtral’s code ability is very strong, so it has also been our focus.
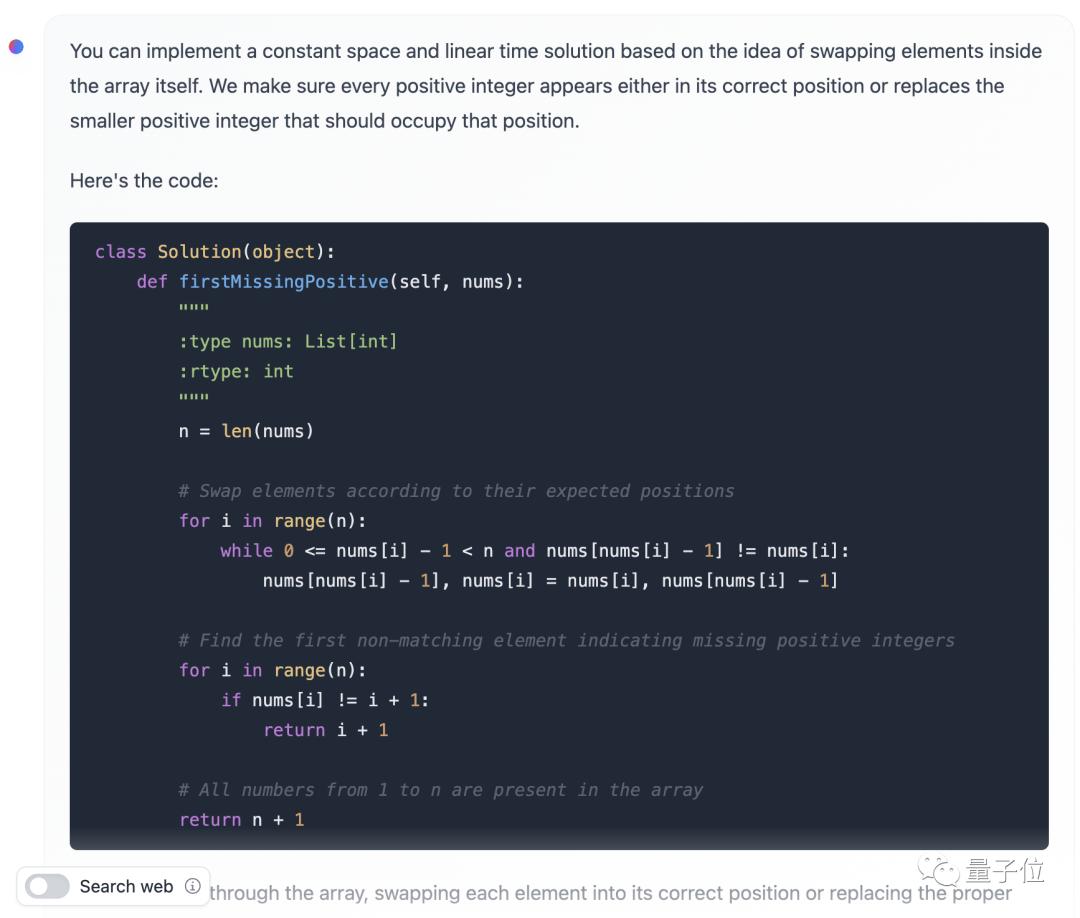
A difficult LeetCode came down, and the code given by Mixtral passed the test once.
Give you an unordered integer array nums, please find out the smallest positive integer that does not appear in it.
Please implement a solution with time complexity of O(n) and only use extra space of constant level.
However, as we continued to ask questions, Mixtral’s answer accidentally revealed that he might have trained specifically for LeetCode, and it was also a Chinese version of LC.

In order to show the code ability of Mixtral more truly, we turn to let it write a utility program-write a Web calculator with JS.
After several rounds of adjustment, although the layout of the buttons is a bit strange, the basic four operations can be completed.

In addition, we will find that if new requirements are constantly added in the same dialog window, the performance of Mixtral may decline, resulting in code format confusion and other problems, and it will return to normal after starting a new round of dialogue.
In addition to API and online version, Mistral AI also provides a model download service, which can be deployed locally by using magnetic link or downloading through Hugging Face.
In the world, many netizens have run Mixtral on their own devices and given performance data.
On an Apple M3 Max device with 128GB of memory, running Mixtral with 16-bit floating-point precision consumes 87GB of video memory and can run 13 token per second.

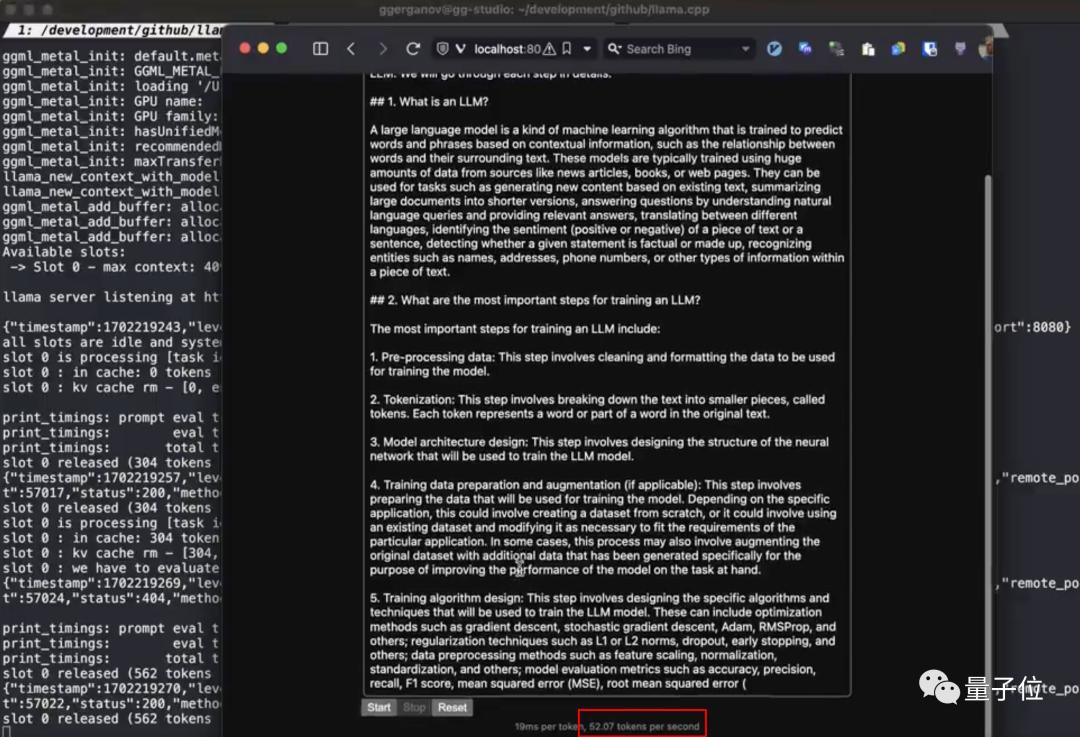
At the same time, some netizens ran out of the speed of 52token per second through llama.cpp on M2 Ultra.
Seeing this, how much would you rate Mistral AI’s model strength?
Many netizens are already excited:
"OpenAI has no moat", which seems certain to come true …

You know, Mistral AI was just established in May this year.
In just half a year, it has been a valuation of $2 billion, which has surprised the model of the entire AI community.
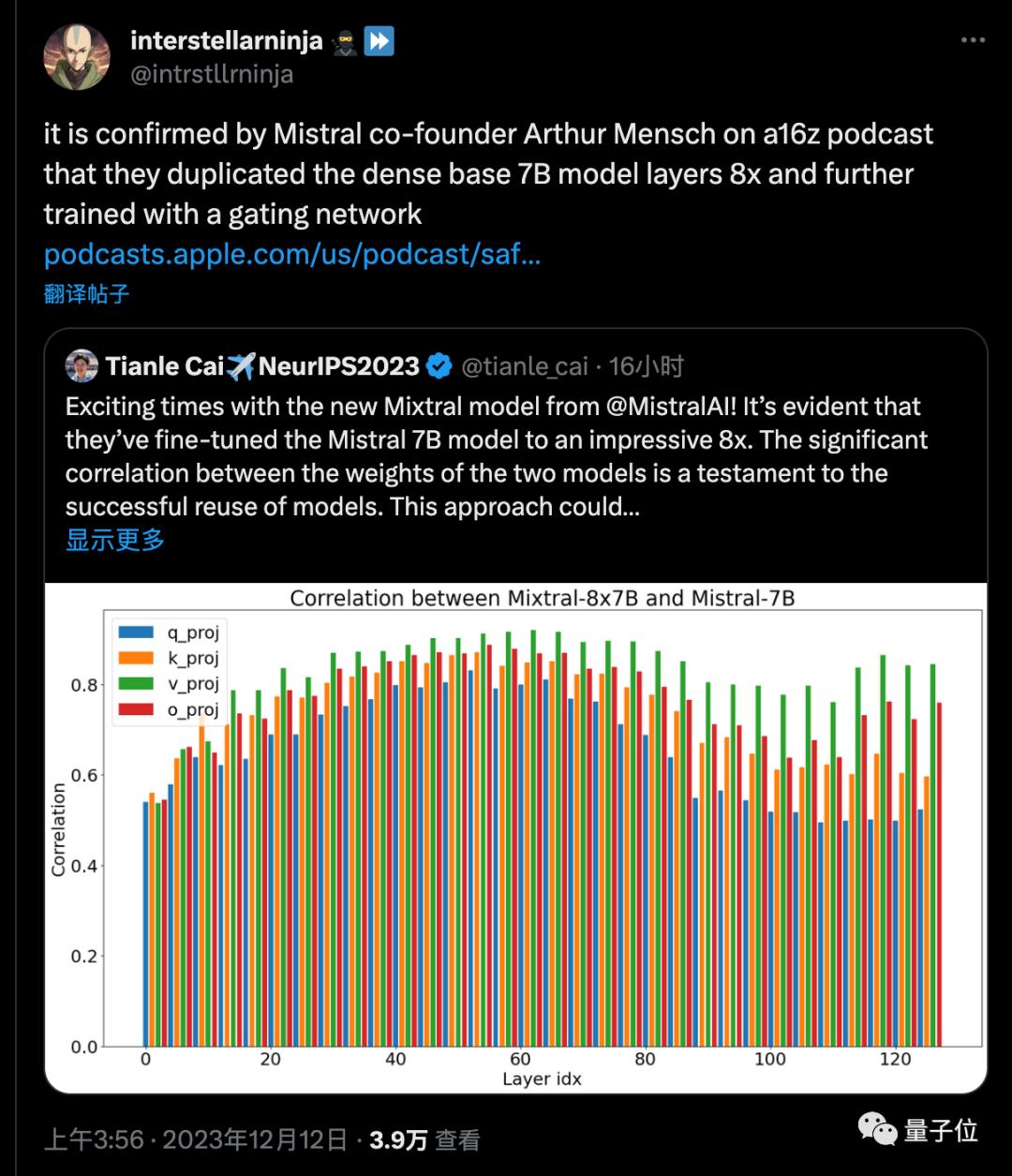
More importantly, Tianle Cai, a Ph.D. student at Princeton, analyzed the weight correlation between Mistral-7B and Mixtral-8x7B models, which proved the successful reuse of the models.
Later, netizens found that the founder of Mistral AI also personally confirmed that the MoE model was indeed a copy of the 7B basic model eight times and then further trained.
With the free commercialization of this model, the whole open source community and new startups can promote the development of MoE model on this basis, just like the storm that Llama has already driven.
As people who eat melons, they can only say:

Reference link:
[1]https://mistral.ai/news/mixtral-of-experts/
[2]https://mistral.ai/news/la-plateforme/
[3]https://huggingface.co/blog/mixtral#about-the-name
End—
Original title: "Open source big model surpasses GPT-3.5! The measured results of MoE are released. Netizen: OpenAI has no moat more and more.
Read the original text